Fonte: https://towardsdatascience.com/introduction-to-knowledge-graph-embedding-with-dgl-ke-77ace6fb60ef
Amazon recently launched DGL-KE, a software package that simplifies this process with simple command-line scripts. With DGL-KE, users can generate embeddings for very large graphs 2–5x faster than competing techniques. DGL-KE provides users the flexibility to select models used to generate embeddings and optimize performance by configuring hardware, data sampling parameters, and the loss function. To use this package effectively, however, it is important to understand how embeddings work and the optimizations available to compute them. This two-part blog series is designed to provide this information and get you ready to start taking advantage of DGL-KE.
Finally, another class of graphs that is especially important for knowledge graphs are multigraphs. These are graphs that can have multiple (directed) edges between the same pair of nodes and can also contain loops. These multiple edges are typically of different types and as such most multigraphs are heterogeneous. Note that graphs that do not allow these multiple edges and self-loops are called simple graphs
A knowledge graph (KG) is a directed heterogeneous multigraph whose node and relation types have domain-specific semantics. KGs allow us to encode the knowledge into a form that is human interpretable and amenable to automated analysis and inference.
Knowledge graph embeddings (KGEs) are low-dimensional representations of the entities and relations in a knowledge graph. They provide a generalizable context about the overall KG that can be used to infer relations.
The knowledge graph embeddings are computed so that they satisfy certain properties; i.e., they follow a given KGE model. These KGE models define different score functions that measure the distance of two entities relative to its relation type in the low-dimensional embedding space. These score functions are used to train the KGE models so that the entities connected by relations are close to each other while the entities that are not connected are far away.
There are many popular KGE models such as TransE, TransR, RESCAL, DistMult, ComplEx, and RotatE, which define different score functions to learn entity and relation embeddings. DGL-KE makes these implementations accessible with a simple input argument in the command line script.
TransE
Translation based embedding model (TransE)
is a representative translational distance model that represents
entities and relations as vectors in the same semantic space of
dimension Rd, where d is the dimension of the target space with reduced
dimension. A fact in the source space is represented as a triplet
(h,r,t) where h is short for the head, r is for the relation, and t is for the tail.
The relationship is interpreted as a translation vector so that the
embedded entities are connected by relation r have a short distance. [3,
4]
In terms of vector computation, it could mean adding a head to a relation should approximate to the relation’s tail or h+r ≈ t.
TransE performs linear transformation and the scoring function is negative distance between:

TransE cannot cover a relationship that is not 1-to-1 as it learns only
one aspect of similarity. TransR addresses this issue with separating
relationship space from entity space where h, t ∈ ℝᵏ and $r ∈ ℝᵈ. The
semantic spaces do not need to be of the same dimension.
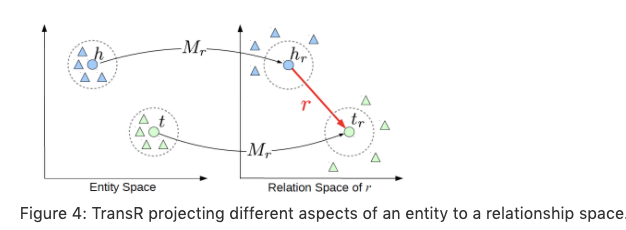
The score function in TransR is similar to the one used in TransE and measures the euclidean distance between h+r and t, but the distance measure is per relationship space.
Fonte: https://towardsdatascience.com/optimize-knowledge-graph-embeddings-with-dgl-ke-1fff4ab275f2
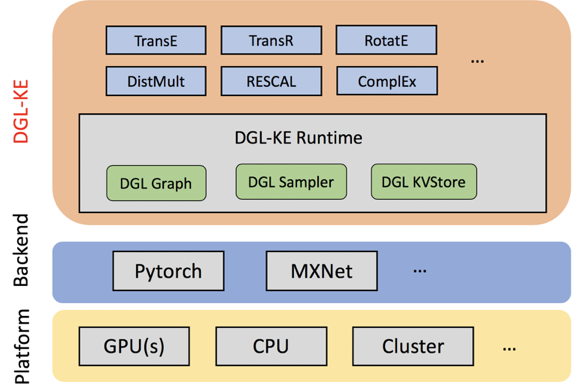
What is DGL-KE
To recap, DGL-KE is a high performance, easy-to-use, and scalable toolkit to generate knowledge graph embeddings from large graphs. It is built on top of the Deep Graph Library (DGL), an open-source library to implement Graph Neural Networks (GNN).
Instalação no VM029
mkdir dgl-ke
cd dgl-ke
conda create -n dgl_pytorch python==3.8
conda activate dgl_pytorch
conda install PyTorch torchvision cudatoolkit=10 -c PyTorch
pip install dgl dglke
python - versionpython>>> import torch
>>> torch.__version__
'1.9.1' >>> import dgl
Using backend: pytorch
>>> import dglke
>>> dgl.__version__, dglke.__version__
('0.6.1', '0.1.2')
>>> quit ()
DGLBACKEND=pytorch
dglke_train --model_name TransE_l2 --dataset FB15k --batch_size 1000 \ --neg_sample_size 200 --hidden_dim 400 --gamma 19.9 --lr 0.25 --max_step 500 \--log_interval 100 --batch_size_eval 16 -adv --regularization_coef 1.00E-09 \--test --num_thread 1 --num_proc 8O teste acima apresentou erro
Using backend: pytorch
Reading train triples....
Finished. Read 483142 train triples.
Reading valid triples....
Finished. Read 50000 valid triples.
Reading test triples....
Finished. Read 59071 test triples.
|Train|: 483142
random partition 483142 edges into 8 parts
part 0 has 60393 edges
part 1 has 60393 edges
part 2 has 60393 edges
part 3 has 60393 edges
part 4 has 60393 edges
part 5 has 60393 edges
part 6 has 60393 edges
part 7 has 60391 edges
/home/cloud-di/miniconda3/envs/dgl_pytorch/lib/python3.8/site-packages/dgl/base.py:45: DGLWarning: Recommend creating graphs by `dgl.graph(data)` instead of `dgl.DGLGraph(data)`.
return warnings.warn(message, category=category, stacklevel=1)
/home/cloud-di/miniconda3/envs/dgl_pytorch/lib/python3.8/site-packages/dgl/base.py:45: DGLWarning: Keyword arguments ['readonly', 'multigraph', 'sort_csr'] are deprecated in v0.5, and can be safely removed in all cases.
return warnings.warn(message, category=category, stacklevel=1)
Traceback (most recent call last):
File "/home/cloud-di/miniconda3/envs/dgl_pytorch/bin/dglke_train", line 8, in <module>
sys.exit(main())
File "/home/cloud-di/miniconda3/envs/dgl_pytorch/lib/python3.8/site-packages/dglke/train.py", line 118, in main
train_sampler_head = train_data.create_sampler(args.batch_size,
File "/home/cloud-di/miniconda3/envs/dgl_pytorch/lib/python3.8/site-packages/dglke/dataloader/sampler.py", line 379, in create_sampler
return EdgeSampler(self.g,
File "/home/cloud-di/miniconda3/envs/dgl_pytorch/lib/python3.8/site-packages/dgl/contrib/sampling/sampler.py", line 683, in __init__
self._sampler = _CAPI_CreateUniformEdgeSampler(
File "dgl/_ffi/_cython/./function.pxi", line 287, in dgl._ffi._cy3.core.FunctionBase.__call__
File "dgl/_ffi/_cython/./function.pxi", line 232, in dgl._ffi._cy3.core.FuncCall
File "dgl/_ffi/_cython/./base.pxi", line 155, in dgl._ffi._cy3.core.CALL
dgl._ffi.base.DGLError: [11:53:32] /opt/dgl/include/dgl/packed_func_ext.h:117: Check failed: ObjectTypeChecker<TObjectRef>::Check(sptr.get()): Expected type graph.Graph but get graph.HeteroGraph
Stack trace:
[bt] (0) /home/cloud-di/miniconda3/envs/dgl_pytorch/lib/python3.8/site-packages/dgl/libdgl.so(dmlc::LogMessageFatal::~LogMessageFatal()+0x4f) [0x7f85552fe03f]
[bt] (1) /home/cloud-di/miniconda3/envs/dgl_pytorch/lib/python3.8/site-packages/dgl/libdgl.so(dgl::GraphRef dgl::runtime::DGLArgValue::AsObjectRef<dgl::GraphRef>() const+0x264) [0x7f85554824a4]
[bt] (2) /home/cloud-di/miniconda3/envs/dgl_pytorch/lib/python3.8/site-packages/dgl/libdgl.so(+0x9b1690) [0x7f8555a97690]
[bt] (3) /home/cloud-di/miniconda3/envs/dgl_pytorch/lib/python3.8/site-packages/dgl/libdgl.so(+0x9b2264) [0x7f8555a98264]
[bt] (4) /home/cloud-di/miniconda3/envs/dgl_pytorch/lib/python3.8/site-packages/dgl/libdgl.so(DGLFuncCall+0x48) [0x7f85559f1d48]
[bt] (5) /home/cloud-di/miniconda3/envs/dgl_pytorch/lib/python3.8/site-packages/dgl/_ffi/_cy3/core.cpython-38-x86_64-linux-gnu.so(+0x15d3e) [0x7f8554c4ed3e]
[bt] (6) /home/cloud-di/miniconda3/envs/dgl_pytorch/lib/python3.8/site-packages/dgl/_ffi/_cy3/core.cpython-38-x86_64-linux-gnu.so(+0x1626b) [0x7f8554c4f26b]
[bt] (7) /home/cloud-di/miniconda3/envs/dgl_pytorch/bin/python(_PyObject_MakeTpCall+0x22f) [0x55e80661331f]
[bt] (8) /home/cloud-di/miniconda3/envs/dgl_pytorch/bin/python(_PyEval_EvalFrameDefault+0x485) [0x55e80669a945]

Comentários
Postar um comentário
Sinta-se a vontade para comentar. Críticas construtivas são sempre bem vindas.