Chen, J., Ke, H., Mo, H., Gao, X., Chen, G. (2022). CAKE: A Context-Aware Knowledge Embedding Model of Knowledge Graph. In: Strauss, C., Cuzzocrea, A., Kotsis, G., Tjoa, A.M., Khalil, I. (eds) Database and Expert Systems Applications. DEXA 2022. Lecture Notes in Computer Science, vol 13426. Springer, Cham. https://doi.org/10.1007/978-3-031-12423-5_4
https://link.springer.com/chapter/10.1007/978-3-031-12423-5_4
Abstract
... In this work, a context-aware knowledge embedding model (CAKE) has been proposed for applications like knowledge completion and link prediction. We model the generative process of KG formation based on latent Dirichlet allocation and hierarchical Dirichlet process, where the latent semantic structure of knowledge elements is learned as contexts. Contextual information, i.e. the context-specific probability distribution over elements, is thereafter leveraged in a translation-based embedding model. ...In this work, the learned embeddings of entities and relations are applied to link prediction and triple classification in experiments and our model shows the best performance compared with multiple baselines.
[A definição de informação contextual é de distribuição de probabilidade sobre os elementos: entidades e relações e aplicada a tarefas para predição de link e classificação de triplas]
[Existe uma formula para entidade, outra para relação e outra para o contexto]
1 Introduction
Knowledge graph (KG) ... triplet-based network ... to unambiguously describe facts extracted from the real world.
[Ainda na visão de triplas somente e tratando como fatos - Verdade Absoluta em CWA]
Knowledge embedding, a genre of methods that show the most promising prospects in solving knowledge sparsity and grit of a specific domain in KG ...
[Para completar o grafo mas não para explorar]
... to improve the embedding accuracy: only part of the attributes of an entity are usable information for inferring a new knowledge. TransR [10] initially proposed such observation and hypothesis, while TransA [13] first explicitly formulated attention mechanism in the scenario of knowledge graph, using a ontology-level prejudgement as well as a relation-specific filtering skill to select only usable components in the latent space.
[Somente parte do grafo seria usada para calcular embeddings, literais são descartados]
In this work, we parallel extend the intuition to entities, assuming that entities and relations in knowledge graph probabilistically associate with a set of semantic components shared by all knowledge elements. We deem that the semantic components are consistent with factual domains for logically sound knowledge graphs; in case of ambiguity, we refer to such objects as contexts in this work, since they essentially interact with observable elements in role of contextual information. On the other hand, relation-specific attention mechanism overlooks meso-level constraints that should have been exerted on elements’ embedding learning. In other words, relations exhibit internal structures w.r.t. their attention properties: compared with the relation assassinate, citeThePaper is more likely to co-occur with the relation coauthorWith and help with relevant inference.
[Premissa: entidades e relações no grafo de conhecimento se associam probabilisticamente a um conjunto de componentes semânticos compartilhados por todos os elementos de conhecimento. As relações exibem estruturas internas (propriedades de atenção) que permitem diferenciar a relação assassinar como menos provável de co-ocorrer com a relação coautorCom do que a relação citeThePaper e isso contribui para inferências]
[Só irei completar a melhor resposta com o Contexto Relativo ou o Contexto Default, como um caso especial de Contexto Relativo]
We formulate this work as a knowledge embedding model for applications like knowledge completion and link prediction, the latter of which is an experimental metrics in this paper. Overall framework of our work is shown in Fig. 1. We use latent Dirichlet allocation and hierarchical Dirichlet process, respectively, to model the generative process of a general knowledge graph, through which the latent semantic structure of knowledge elements is learned as contexts.
[O contexto aqui não está relacionado com a noção de verdade e utilidade que estamos abordando na exploração]
Contextual information, i.e. the context-specific probability distribution over elements is thereafter leveraged in a translation-based embedding model. The learned embeddings of entities and relations are applied to link prediction and triple classification.
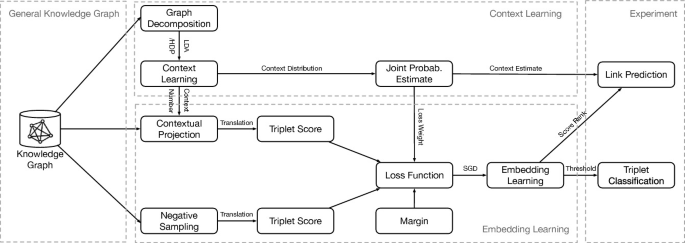
2 Related Work
Existing methods on knowledge embedding are chronologically enumerated and analyzed in this section. Since the proposed CAKE model is a translation-based embedding model (also the most mainstream model family), we mainly review previous studies along the branch while introduce other methods selectively.
[Do tipo translacional, é uma família Trans*]
Another genre of studies seek to gain information from temporal and spatial factors based on the observation that facts only holds true within a timespan (or took place at a specific moment if the relation is instant). Jiang et al. [8] take into account the temporal priority between two facts w.r.t. a head entity and assumes that embedding of a previous relation associated to the entity can transform into a temporally subsequent one via a transition matrix. They first consider temporal factor in knowledge embedding, but failed to explicitly leverage temporal knowledge. HyTE [2] points out the drawback and proposes a novel model where discretized timestamps are depicted by hyperplanes in the semantic space. Projections of (embeddings of) head, relation and tail onto the hyperplane are trained to obey the translation rule.
[Considerando dimensões contextuais específicas como tempo e espaço]
3 Context-Aware Knowledge Embedding (CAKE)
This section introduces our context-aware knowledge embedding models and the methods our models based on. First we introduce LDA-based and HDP-based context learning methods. Then we develop the context-aware embedding models by deriving its loss function and negative sampling algorithms. We will give the optimization in the end.
3.1 LDA-Based Context Learning
Latent Dirichlet Allocation, known as a generative probabilistic model for collections of discrete data, leverages a three-layer hierarchical Bayesian framework to model the formation of internally-structured data such as corpus and human populations (with haplotype). Teh et al. [17] refers to the corresponding inference problem as Grouped Clustering Problems (GCP). The problem is formulated as: given a fully observable knowledge graph Gi, with a specified context number K and the prior distribution parameters α and β, we aim to learn the parameters of the multinomial distributions and w.r.t. both entities and relations.
[Contexto é um valor, não é semântico]
3.2 HDP-Based Context Learning
Dirichlet process (DP) is in a sense an infinitely dimensional generalization of Dirichlet distribution, normally specified by a base distribution G and a concentration parameter α. The formal mathematical definition of DP is as follows. Given a measurable set Ω, a base probability distribution G0 and a positive real number α, if for any measurable finite partition of Ω (denoted by (Ai, A2, …, An)) it holds that (G(A1),…,G(An))∼Dir(αG0(A1),…,αG0(An)) Specifically, Dir(⋅) represents Dirichlet distribution. Then, G∼DP(G0,α), that is, G is subject to the Dirichlet process with base distribution G0 and concentration parameter α.
HDP-Based Context Learning. Similar to LDA-based context learning model, HDP-based context learning problem can be formulated as: given a fully observable knowledge graph G, a continuous base distribution G and hierarchical concentration parameters α and α0, we aim to learn the context number activated by observed elements in G as well as the multinomial distribution parameters θ characterizing the aforementioned contexts.
[Contexto é um valor, não é semântico]
3.3 Context-Aware Knowledge Embedding
We define a semantic hyperplane for each context and characterize the cth context with its normal vector, denoted by ωc. We inherit the form and notation of triplets as (h, r, t) where h, r and t represent the head entity, relation and the tail entity, respectively. To enable knowledge entities to own multiple interpretations in various contexts, we denote the projections of head h, relation r and tail t onto the hyperplane corresponding to context c by Pc(eh)=eh−(ω⊤ceh)ωc, Pc(er)=er−(ω⊤cer)ωc, Pc(et)=et−(ω⊤cet)ωc. Similar to TransR, we deem that the projection operation provides a semantic reflection of the knowledge element, through which the distribution over latent semantic space is altered. We then exert the classic translation rule on the semantic reflections of the original embeddings.
[Contexto é a projeção da tripla em cada dimensão, forma uma nova dimensão]
Note that such distance (or score) not only measures the validity of a given triplet, but also describes conformity of the given triple belonging to a specified context. Although the mechanism is not rigorously defined as attention, this layer equivalently serves model by selectively filtering information. The model automatically determine the probability of a triplet showing up in a specific context and thereby decide whether utilize the corresponding contextual information for embedding learning and inference. Contexts are learned a priori and the joint probability of a given triplet automatically adjust the loss distribution over different contexts. To effectively leverage the associations between knowledge elements and contexts, we add probabilistic components into the modified loss function.
[Aqui é mais intrincado, como aprender o contexto usando o grafo?]
The result of LDA-and-HDP-based context learning is the probability distribution of contexts over all knowledge elements. For context c, we denote its probability distribution over entity as Fεc(ϵ), where the superscript ε indicates the element type. Similarly, we denote the probability distribution over relation as FRc(r). As contexts are learned with a “word-of-bag” model, we deem that the probability of an entity belonging to a context and that of a relation is independent.
We now discuss the interpretation of the joint probability of a given triplet with regard to context c. If pc(h,r,t) is relatively large, then entity h, t and relation r are highly likely to co-occur in context c; this intuitively indicates that the fact determined by this triplet is more likely to make sense and have practical interpretations.
[A tripla / fato tem mais probabilidade de existir no contexto ... mas nesse caso qual contexto?]
We use the joint probability as a weight parameter for positive triplets. In this way, the triplets that are more semantically reasonable can be highlighted in the training process, enhancing the coherence of the corresponding context. For a negative triplet (h,r,t′), a large pc(h,r,t′) value indicates that the three elements are semantically related in the context c but the fact does not hold true. In contrast, a small pc(h,r,t′) means neither the elements are semantically linked, nor the fact is real.
Considering optimization, the loss function of CAKE can be optimized with stochastic gradient descent (SGD) by calculating the gradients and selecting a proper learning rate. Entity embedding, relation embedding and normal vectors of each hyperplane associated to contexts need to be learned through the training process.
4 Experimental Evaluation
This section describes the experimental protocol, metrics and experimental results of our method (CAKE) as well as four baselines (TransE, TransH, TransR, TransAt). We conduct extensive experiments for two tasks, link prediction and triplet classification, on two datasets, Freebase and AceKG. We show the experimental results in the last subsection of this part, and present sufficient analysis based on observations and complementary tests.
[Dois datasets baseados em triplas, duas tarefas]
[Em RDF mas não comenta sobre o impacto da reificação na geração de embeddings]
[Selecionou 4 algoritmos para baseline mas pq esses 4 e não outros?]
4.1 Experiment Protocol
Following [13], we evaluate the performance of proposed CAKE on two tasks, link prediction and triplet classification.
We conducted experiments on both the Freebase and the AceKG subset for link prediction with metrics Hit@10 and Mean Rank and for triplet classification with metrics F1-score. For all the 5 methods, we experiment with margin value as {1,2,3,4,5,6} and the learning rate of {0.001,0.005,0.01} respectively. For our method CAKE, we apply the hyperparameter κ as values from {1,1.5,2,3}, and set context number as {10,20,30} for LDA-based CAKE. Latent dimension number was set as {50,100,200} respectively. We uniformly used batches with the size of 150 and trained each model for 2000 epoch for convergence.
4.2 Experiment Settings
Datasets. Freebase and AceKG [18] datasets are utilized in experiments, the former of which is known as an endeavor of general knowledge graph while the latter is an academy- oriented one, containing authors, papers, citation relationships and academic fields. We briefly introduce them as follows. For experiments, We extracted a tractable subset of Freebase with 24, 624 entities, 351 relations and 194, 328 facts; and a small subset of AceKG containing 30, 752 entities, 7 relations and 146, 917 facts.
Baselines. We use representative graph embedding models, TransE [1], TransH [20], TransR [10] and TransAt [13] as baselines in this work to testify the effectiveness of our proposed model CAKE.
Metrics. For three link prediction settings, we use Hits@10 and Mean Rank, and for triplet classification, we use F1-score to validate models’ effectiveness.
4.3 Experimental Results
<...>
5 Conclusion
... The model automatically determines the probability of a triplet showing up in a specific context and thereby decide whether utilize the corresponding contextual information for embedding learning and inference. (2) The model learns knowledge representations based on contextual information since contexts are learned a priori and the joint probability of a given triplet automatically adjust the loss distribution over different contexts.
[Difícil correlacionar com o meu problema de pesquisa, seria o caso de dado um contexto verificar se a tripla atende?]

Comentários
Postar um comentário
Sinta-se a vontade para comentar. Críticas construtivas são sempre bem vindas.