Čebirić, Š., Goasdoué, F., Kondylakis, H. et al. Summarizing semantic graphs: a survey. The VLDB Journal 28, 295–327 (2019). https://doi.org/10.1007/s00778-018-0528-3
Abstract
The explosion in the amount of the available RDF data has lead to the need to explore, query and understand such data sources. Due to the complex structure of RDF graphs and their heterogeneity, the exploration and understanding tasks are significantly harder than in relational databases, where the schema can serve as a first step toward understanding the structure.
[Conhecer o esquema ajuda na exploração]
Summarization has been applied to RDF data to facilitate these tasks. Its purpose is to extract concise and meaningful information from RDF knowledge bases, representing their content as faithfully as possible. There is no single concept of RDF summary, and not a single but many approaches to build such summaries; each is better suited for some uses, and each presents specific challenges with respect to its construction.
[Várias abordagens para gerar o esquema]
Introduction
A famous repository of open RDF graphs is the Linked Open Data Cloud, currently referencing more than 62 billion RDF triples, organized in large and complex RDF data graphs. Further, several RDF graphs are conceptually linked together into one, as soon as a node identifier appears in several graphs. This enables querying KBs together, and increases the need to understand the basic properties of each data source before figuring out how they can be exploited together.
[Em escala de Big Data por volume e integração de dados por isso é KG e não KB]
The fundamental difficulty toward understanding an RDF graph is its lack of a standard structure (or schema), as RDF graphs can be very heterogeneous and the basic RDF standard does not give means to constrain graph structure in any way. Ontologies can (but do not have to) be used in conjunction with RDF data graphs, in order to give them more meaning, notably by describing the possible classes resources may have, their properties, as well as relationships between these classes and properties. On the one hand, ontologies do provide an extra entry point into the data, as they allow to grasp its conceptual structure. On the other hand, they are sometimes absent, and when present, they can be themselves quite complex...
[Não possuem esquema ou não possuem um único esquema. Quando possuem são complexos para exploração]
To cope with these layers of complexity, RDF graph summarization has aimed at extracting concise but meaningful overviews from RDF KBs, representing as close as possible the actual contents of the KB. RDF summarization has been used in multiple application scenarios, such as identifying the most important nodes, query answering and optimization, schema discovery from the data, or source selection, and graph visualization to get a quick understanding of the data. ... therefore, several summarization methods initially studied for data graphs were later adapted to RDF.
[Algoritmos de grafo em geral aplicados a RDF]
Some summarize an RDF graph into a smaller one, allowing some RDF processing (e.g., query answering) to be applied on the summary (also). The output of other summarization methods is a set of rules, or a set of frequent patterns, an ontology etc.
[Várias saídas do processo de sumarização]
To improve understanding of this field and to help students, researchers or practitioners seeking to identify the summarization algorithm, method or tool best suited for a specific problem, this survey attempts to provide a first systematic organization of knowledge in this area.
[Problemas terminológicos dificultam a pesquisa nessa área ... eu imaginei que usariam termos de BD como Engenharia Reversa ... ]
Preliminaries: RDF graphs

The RDFS constraints depicted in Fig. 2 are interpreted under the open-world assumption (OWA), i.e., as deductive constraints. For instance, if the triple (hasFriend,↩d,Person) and the triple (Anne,hasFriend,Marie) hold in the graph, then so does the triple (Anne,τ,Person). The latter is due to the domain constraint in Fig. 2
[A interpretação OWA permite inferir o tipo baseado no esquema RDFS]
RDF entailment
An important feature of RDF graphs are implicit triples. Crucially, these are considered part of the RDF graph even though they are not explicitly present in it, e.g., the dashed-line G edges in Fig. 3, hence require attention for RDF graph summarization. ... W3C names RDF entailment the mechanism through which, based on a set of explicit triples and some entailment rules, implicit RDF triples are derived.
[Inferência de novas triplas mesmo não estando afirmadas no KB por meio do esquema]
Instance and schema graph
An RDF instance graph is made of assertions only ..., while an RDF schema graph is made of constraints only (i.e., it is an ontology). Further, an RDF graph can be partitioned into its (disjoint) instance and schema subgraphs.
[ABox - instâncias, TBox - esquema]
Query answering
The evaluation of Q against G uses only G’s explicit triples, thus may lead to an incomplete answer set. The (complete) answer set of Q against G is obtained by the evaluation of Q against G∞, denoted by Q(G∞).
[A melhor resposta também deve considerar as triplas inferidas ... Semantic Rules]
OWL
Semantic graphs considered in the literature for summarization sometimes go beyond the expressiveness of RDF, which comes with the simple RDF Schema ontology language. The standard by W3C for semantic graphs is the OWL family of dialects that builds on Description Logics (DLs).
DLs are first-order logic languages that allow describing a certain application domain by means of concepts, denoting sets of objects, and roles, denoting binary relations between concept instances. DL dialects differ in the ontological constraints they allow expressing on complex concepts and roles, i.e., defined by DL formula. One of the most important issues in DLs is the trade-off between expressive power and computational complexity of reasoning with the constraints (consistency checking, query answering, etc.)
[Não basta usar RDF]
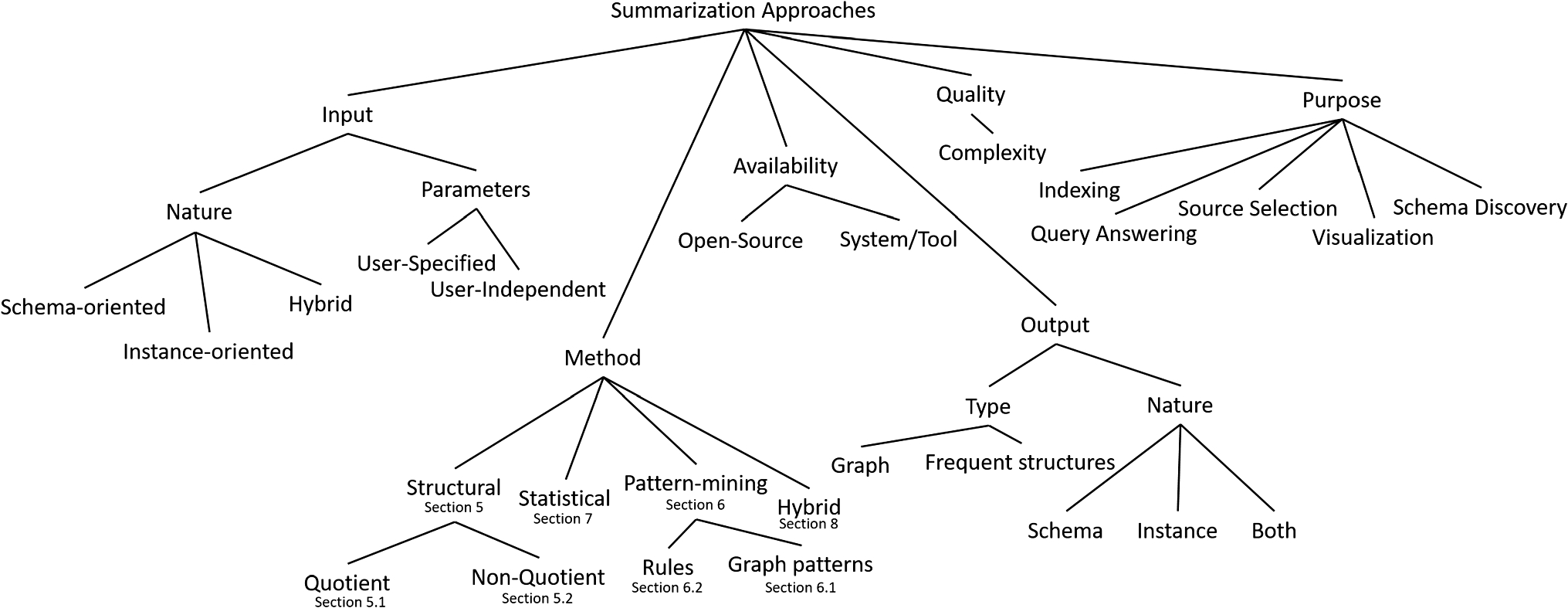
RDF summarization: scope, applications and dimensions of analysis for this survey
An RDF summary is one or both among the following:
1. A compact information, extracted from the original RDF graph; intuitively, summarization is a way to extract meaning from data while reducing its size;
2. A graph, which some applications can exploit instead of the original RDF graph, to perform some tasks more efficiently; in this vision, a summary represents (or stands for) the graph in specific settings.
Clearly, these notions intersect, e.g., many graph summaries extracted from the RDF graphs are compact and can be used for instance to make some query optimization decisions; these fit into both categories. However, some RDF summaries are not graphs; some (graph or non-graph) summaries are not always very compact, yet they can be very useful etc.
[Definição que nem sempre acompanha o resultado prático]
Applications - [Propósito]
Indexing: ... build summaries which are smaller graphs; each summary node represents several nodes of the original graph G. This smaller graph, then, serves as an index...
Estimating the size of query results: consider a summary defined as a set of statistics .... If a query searches,..., if the summary indicates that there are no such resources, we can return an empty query answer without consulting G. ... If the summary shows that the former property combination is much rarer than the latter, a query optimizer can exploit this to start evaluating the query from the most selective conditions.
[Responder sem acessar o Grafo G, acessando somente o sumário g OU Otimizar o acesso a G com base nas estatísticas g ... Eficiência]
Making BGPs more specific: a graph summary may help understand, e.g., that a path specified as “any number of a edges followed by one or more b edges” corresponds to exactly two data paths in G ...
Source selection: One can detect based on a summary whether a graph is likely to have a certain kind of information that the user is looking for, without actually consulting the graph.
[Útil para a melhor resposta]
Graph visualization: graph-shaped summary may be used to support the users’ discovery and exploration of an RDF graph, helping them get acquainted with the data and/or as a support for visual querying.
[usado em abordagens de KG exploration]
Vocabulary usage analysis: RDF is often used as a mean to standardize the description of data from a certain application domain ... . A standardization committee typically works to design a vocabulary (or set of standard data properties) and/or an ontology ... the standard designers are interested to know which properties and ontology features were used, and which were not; this can inform decisions about future versions of the standard.
[Sobre a utilização dos padrões de metadados ... mas poderia ser para identificar o padrão de fato em uso]
Schema (or ontology) discovery: When an ontology is not present in an RDF graph, some works aim at extracting it from the graph. In this case, the summary is meant to be used as a schema, which is considered to have been missing from the initial data graph.
[Engenharia Reversa]
Classification of RDF summarization methods
... main algorithmic idea behind the summarization method:
1. Structural methods are those which consider first and foremost the graph structure, respectively the paths and subgraphs one encounters in the RDF graph.
a) Quotient - They allow characterizing some graph nodes as “equivalent“ in a certain way, and then summarizing a graph by assigning a representative to each class of equivalence of the nodes in the original graph. ...
b) Non-quotient - ... based on other measures, such as centrality, to identify the most important nodes, and interconnect them in the summary. Such methods aim at building an overview of the graph, even if (unlike quotient summaries) some graph nodes may not be represented at all.
[Exploram a topologia do grafo]
2. Pattern-mining methods These methods employ mining techniques for discovering patterns in the data; the summary is then built out of the patterns identified by mining.
[Padrões podem ajudar a identificar contexto default?]
3. Statistical methods These methods summarize the contents of a graph quantitatively. The focus is on counting occurrences, such as counting class instances or building value histograms per class, property and value type; other quantitative measures are frequency of usage of certain properties, vocabularies, average length of string literals etc. Statistical approaches may also explore (typically small) graph patterns, but always from a quantitative, frequency-based perspective.
[Frequencia de valores podem ajudar a identificar regras de interpretação e sugerir contexto default?]
Another interesting dimension of analysis is the required input by each summarization method, in terms of the actual dataset, and of other user inputs which some methods need:
1. Input parameters Many works in the area require user parameters to be defined, e.g., user-specified equivalence relations, ...
2. Input Dataset Different works have different requirements from the dataset they get as input. RDF data graphs are most frequently accepted, .... For instance, the instance and schema information can be used to compute the summary of the saturated graph, even if the instance graph is not saturated.
[Algum trabalha com named graph como entrada? Como a reificação é tratada nesses casos?]
For what concerns the summarization output, we identify the following dimensions:
1. Type ... The summary is sometimes a graph, while in other cases it may be just a selection of frequent structures such as nodes, paths, rules or queries.
2. Nature .... summaries which only output instance representatives, from those that output some form of summary a posteriori schema, and from those that output both.
[O tipo de saída gerada]
Availability ... This will allow a direct comparison with future similar tools:
1. System/tool Several summarization approaches are made available by their authors as a tool or system shared with the public; in our survey, we signal when this is the case. In addition, some of the summarization tools can be readily tested from an online deployment provided by the authors.
2. Open source The implementation of some summarization methods is provided in open source by the authors, facilitating comparison and reuse.
[Ferramenta fechada ou sistema de código aberto]
Generic graph (non-RDF) summarization approaches
Structural graph summarization
The structural complexity and heterogeneity of graphs make query processing a challenging problem, due to the fact that nodes which may be part of the result of a given query can be found anywhere in the input graph. To tame this complexity and direct query evaluation to the right subsets of the data, graph summaries have been proposed as a basis for indexing, by storing next to each summary node, the IDs of the original graph nodes summarized by this node; this set is typically called the extent. Given a query, evaluating the query on the summary and then using the summary node extents allows obtaining the final query results.
[Eficiência]
OLAP and data mining techniques applied to data graphs have considered them through global, aggregated views, looking for statistics and/or trends in the graph structure and content
Structural RDF summarization
Structural summarization of RDF graphs aims at producing a summary graph, typically much smaller than the original graph, such that certain interesting properties of the original graph (connectivity, paths, certain graph patterns, frequent nodes etc.) are preserved in the summary graph. Moreover, these properties are taken into consideration to construct a summary
Inspired by text summarization and information retrieval
One way of summarizing data, especially when the summary is meant for human users, is to select a most significant subset thereof. Such summarization is very useful, considering that the human ability to process information does not change as the available data volumes grow. We describe here RDF knowledge base summarization efforts inspired from information retrieval and text summarization.
[Modelos inspitados em IR]
In [95], the authors study the problem of selecting the most important part of an RDF graph which is to be shown to a user interested in a certain entity (resource). A fixed space (triple) budget is to be used; beyond labels, authors also allow the edges of the RDF graph to carry weights, with higher-weight edges being more important to show. The authors provide algorithms which select triples favoring closeness to the target entity and weight; then, they extend this with criteria based on diversity (include edges with different labels in the selection) and popularity (favor frequently occurring edge labels). It is worth noting that similar techniques have recently been included in Google’s search engine, when the user searches for an entity present in Google’s Knowledge Graph, and is presented with a small selection of this entity’s properties.
Besides this, text summarization principles, where a text can be seen as a collection of terms or a bag of sentences, have been applied to summarize ontologies. An ontology summarization method along these lines is introduced in [116], based on RDF Sentence Graphs. An RDF Sentence Graph is a weighted, directed graph where each vertex represents an RDF sentence, which is a set of RDF Schema statements ... Then, the importance of each RDF sentence is assessed by determining its centrality in the sentence graph. The authors compare different centrality measures (based on node degree, betweenness, and the PageRank and HITS scores, and show that weighted in-degree centrality and some eigenvector-based centralities produce better results. Finally, the most important RDF sentences are re-ranked considering the coherence of the summary and the coverage of the original ontology, and the constructed result is returned to the user.
Focused on centrality measures
RDFDigest ... produces summaries of RDF schemas, consisting of the most representative concepts of the schema, seen also from the angle of their frequency in a given instance (RDF graph). Thus, the input of the process includes both an ontology and a data graph. The tool starts by saturating the knowledge base with all implicit data and schema information, thus taking them into account for the rest of the process. The goal of the work is to identify the most important nodes in the ontology, and to link them in order to produce a valid subgraph of the input schema.
[Inferem as triplas implícitas ... saturação ... para depois realizar os cálculos]
Oriented toward schema extraction -> create schema-like structures
One of the challenges when working with Linked Open Data is the lack of a concise schema, or a clear description of the data that can be found in the data source. SchemEX ..., an indexing and schema extraction tool for the LOD cloud, attempts to solve this problem. Out of an RDF graph, it produces a three-layered index, based on resource types. Each layer groups input data sources of the LOD cloud into nodes, as follows: (i) in the first layer, each node is a single class c from the input, to which the data sources containing triples whose subject is of type c are associated; (ii) in the second layer, each node, now named as an RDF type cluster, is a set of classes C mapped to those data sources having instances whose exact set of types is C; (iii) in the third layer, each node is an equivalence class, where: two nodes u and v from the input belong to the same equivalence class if and only if they have the exact same set of types, they are both subjects of the same data property p, and the objects of that property p belong to the same RDF type cluster. Further, each equivalence class is mapped to all data sources comprising of triples (s,p,o) from an input RDF graph, such that s belongs to the equivalence class of the node. To build the index, a stream-based computation approach is proposed, depicted in Fig. 10. .... Finally, the time complexity of the approach is O(N∗logN) or O(M∗logM), where N is the number of RDF classes available and M is the number of properties.
[Em camadas como a abordagem de exploração via interface]
Toward the same goal of building a compact representation of an RDF graph to be used as a schema, [39] proposes an approach to extract a schema-like directed graph, as follows. A density-based clustering algorithm is used on the input RDF graph to identify the summary nodes: each such node, called a (derived) type, corresponds to a set of resources with sufficient structural similarity. Further, each of these types is described by a profile, i.e., a set of (property, probability) pairs of the form (p→,α) or (p←,α) meaning that a resource of that type has the outgoing or incoming property p with probability α. These profiles are used to define output schema edges of two kinds: (i) There is a p-labeled edge from a type node T1 to a type node T2, i.e., T1−→pT2, whenever p is an outgoing property of T1’s profile and an incoming property of T2’s profile. (ii) There is an rdfs:subClassOf-labeled edge from a type node T1 to a type node T2, i.e., T1−→−−−−−−−−rdfs:subClassOfT2, whenever T1 is found more specific than T2 by an ascending hierarchical clustering algorithm applied to their profiles. The time complexity of the corresponding algorithm is O(N2) where N is the number of entities in the dataset. The output directed graph can be seen as a summary describing first, types which correspond to structurally similar resources, and second, how properties relate resources of various types.
Pattern-based RDF summarization
In this section, we review summarization methods based on data mining techniques, which extract the frequent patterns from the RDF graph, and use these patterns to represent the original RDF graph. A frequent pattern, usually referred to as a knowledge pattern in the RDF/OWL KB context (or simply pattern from now on), characterizes a set of instances in an RDF data graph that share a common set of types and a common set of properties. It is usually modeled as a star BGP of the form {(x,τ,c1),…,(x,τ,cn),(x,Pr1,?b1),…,(x,Prm,?bm)} denoting some resource x having types c1,…,cn and properties Pr1,…,Prm. Given an RDF graph G, a pattern KP identifies all the G resources that match x in the embeddings of KP into G; the number of such embeddings is called the support of KP in G. Patterns identified in such a manner become representative nodes (supernodes).
Mining graph patterns
Zneika et al. present an approach for RDF graph summarization based on mining a set of approximate graph patterns that “best” represent the input graph; the summary is an RDF graph itself, which allows to take advantage of SPARQL to evaluate (simplified) queries on the summary instead of the original graph. The approach proceeds in three steps, as shown in Fig. 11. First, the RDF graph is transformed into a binary matrix. In this matrix, the rows represent the subjects and the columns represent the predicates. The semantics of the information is preserved, by capturing the available distinct types and all attributes and properties (capturing property participation both as subject and object for an instance). Second, the matrix created in the previous step is used in a calibrated version of the PaNDa+ [61] algorithm, which allows to retrieve the best approximate RDF graph patterns, based on different cost functions. Each extracted pattern identifies a set of subjects (rows), all having approximately the same properties (columns). The patterns are extracted so as to minimize errors and to maximize the coverage (i.e., provide a richer description) of the input data. A pattern thus encompasses a set of concepts (type, property, attribute) of the RDF dataset, holding at the same time information about the number of instances that support this set of concepts. Based on the extracted patterns and the binary matrix, the summary is reconstructed as an RDF graph, enriched with the computed statistic information; this enables SPARQL query evaluation on the summary to return approximate answers to queries asked on the original graph. The time complexity of the approach is O(M∗N+K∗M2∗N), where K is the maximum number of patterns to be extracted, M and N are, respectively, the number of distinct properties and subjects/resources in the original KB. The authors note that the algorithm works equally well on homogeneous and heterogeneous RDF graphs.
In [90], the goal is to discover the k patterns which maximize an informativeness measure (an informativeness score function is provided as input). The algorithm takes as input an integer distance in d, which will be used to control the neighborhoods in which we will look for similar entities, and a bound k as the maximum number of the desired patterns. The algorithm discovers the kd-summaries/patterns that maximize the informativeness score function.
The authors use d-similarity to capture similarity between entities in terms of their labels and neighborhood information up to the distance d. Compared to other graph patterns like frequent graph patterns, (bi)simulation-based, dual- simulation-based and neighborhood-based summaries, d-similarity offers greater flexibility in matching, while it takes into account the extended neighborhood, something that provides better summaries especially for schema-less knowledge graphs, where similar entities that are not equivalent in a strict pairwise manner. A node v of the original graph G is attributed to the base graph of the d-summary P if and only if there is a node u of P which has the same label as v and for every parent/child u1 of u in P, there exists a parent/child v1 of v in G such that edges (u1,u) and (v1,v) have the same edge label. Then the d-summaries are used, e.g., to facilitate query answering.
A d-summary P is said to dominate another d-summary P′ if and only if supp(P)≥supp(P′); a maximal d-summary P is one that dominates any summary P′ that may be obtained from P by adding one more edge. The algorithm starts by discovering all maximal d-summaries by mining and verifying all k-subsets of summaries for the input graph G, then greedily adds a summary pair (P, P1) that brings the greatest increase to the informativeness score of the summary. The time complexity of the approach is O(S∗(b+N)∗(b+M)+K2∗S2), where N, M are, respectively, the total number of nodes (subject and objects) and edges (triples) of the original RDF graph, and S is the number of possible d-summaries whose size is bounded by b.
Mining rules
Methods described here use rule mining techniques in order to extract rules for summarizing the RDF graph. A common limitation of such methods is that, by design, the summary is not an RDF graph, thus it cannot be exploited using the common set of RDF tools (e.g., SPARQL querying, reasoning etc.)
Statistical summarization
A first motivation for statistical summarization works comes from the source selection problem. In general, statistical methods are interested in providing quantitative statistics on the content of the KBs in order to decide if it is pertinent to use the KB or not. In that respect, compared to the pattern-mining category (which is conceptually close) and the other categories, it has the advantage not to care too much about issues of structural completeness of the summary and thus reducing computational costs.
[Decidir se o KG responde ou não a determinada query]


Comentários
Postar um comentário
Sinta-se a vontade para comentar. Críticas construtivas são sempre bem vindas.