Como medir similaridade de pares de documentos de modo matemático permitindo comparabilidade entre os níveis de similaridade?
Função de Similaridade
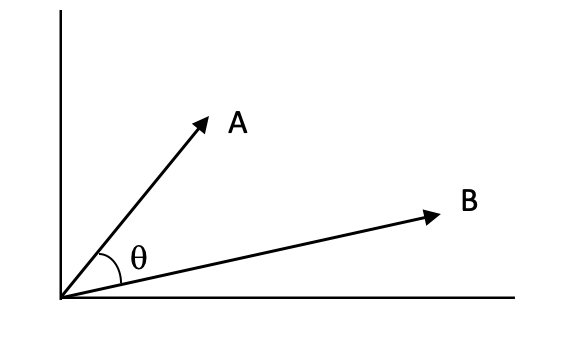
- Distância / Semelhança do cosseno - É o cosseno do ângulo entre dois vetores, que nos dá a distância angular entre os vetores. O cosseno é 1 em teta = 0 e -1 em teta = 180, o que significa que, para dois vetores sobrepostos, o cosseno será o mais alto e o mais baixo para dois vetores exatamente opostos. Por esse motivo, é chamada de similaridade. Você pode considerar 1 - cosseno como distância.
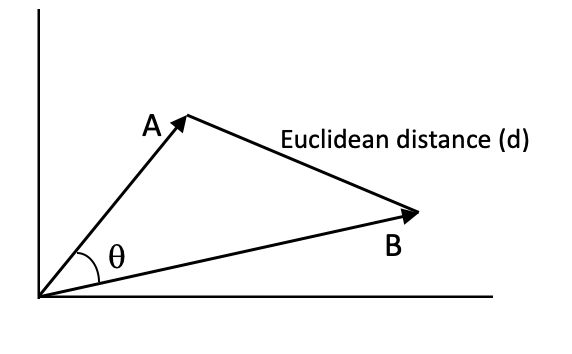
- Distância Euclidiana
- Distância de Jaccard - Índice de Jaccard é usado para calcular a similaridade entre dois conjuntos finitos. A distância de Jaccard pode ser considerada como 1 - Índice de Jaccard.
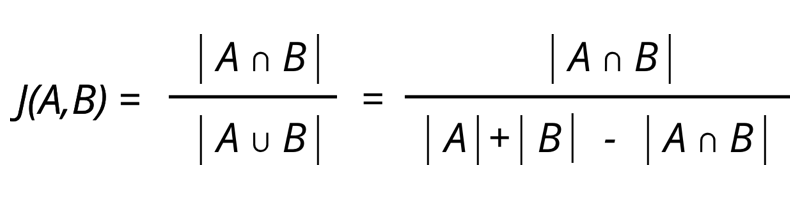
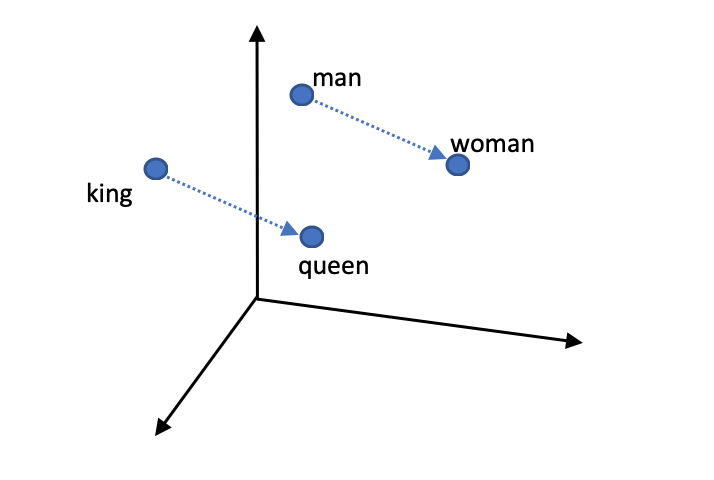
Embeddings
Embeddings são representações vetoriais de texto em que palavras ou frases com significado ou contexto semelhantes têm representações semelhantes.
- Tf-idf - Tf-idf é uma combinação de frequência de termo e frequência inversa de documento. Ele atribui um peso a cada palavra no documento, que é calculado usando a frequência dessa palavra no documento e a frequência dos documentos com essa palavra em todo o corpus de documentos.
O pacote sklearn permite trabalhar com tdf-idf e as funções de similaridade
from sklearn.metrics.pairwise import cosine_similarity
from sklearn.metrics.pairwise import euclidean_distances
from sklearn.feature_extraction.text import TfidfVectorizer
- Word2vec - como o nome sugere, o word2vec incorpora palavras no espaço vetorial. Word2vec pega um corpus de texto como entrada e produz embeddings de palavras como saída. Existem dois algoritmos de aprendizagem principais no word2vec: continuous bag of words (CBW) and continuous skip gram
É possível treinar os próprios embeddings se houverem dados e computação suficientes ou usar embeddings pré-treinados como as fornecida pelo Google. Depois disso é necessário converter cada palavra de nosso corpus de documento em um vetor de 300 dimensões e cada documento como um único vetor. Podemos calcular a média ou somar cada vetor de palavras e converter cada representação de 64X300 em uma representação de 300 dimensões. Uma maneira de fazer isso seria obter uma média ponderada de vetores de palavras usando os pesos tf-idf (MAS isso pode lidar com o problema de comprimento variável até certo ponto, mas não pode manter o significado semântico e contextual das palavras). Usar as distâncias de pares para calcular similaridade de documentos.
- GloVe - Vetores globais para incorporação de palavras (GloVe) é um algoritmo de aprendizagem não supervisionado para produzir representações vetoriais de palavras.
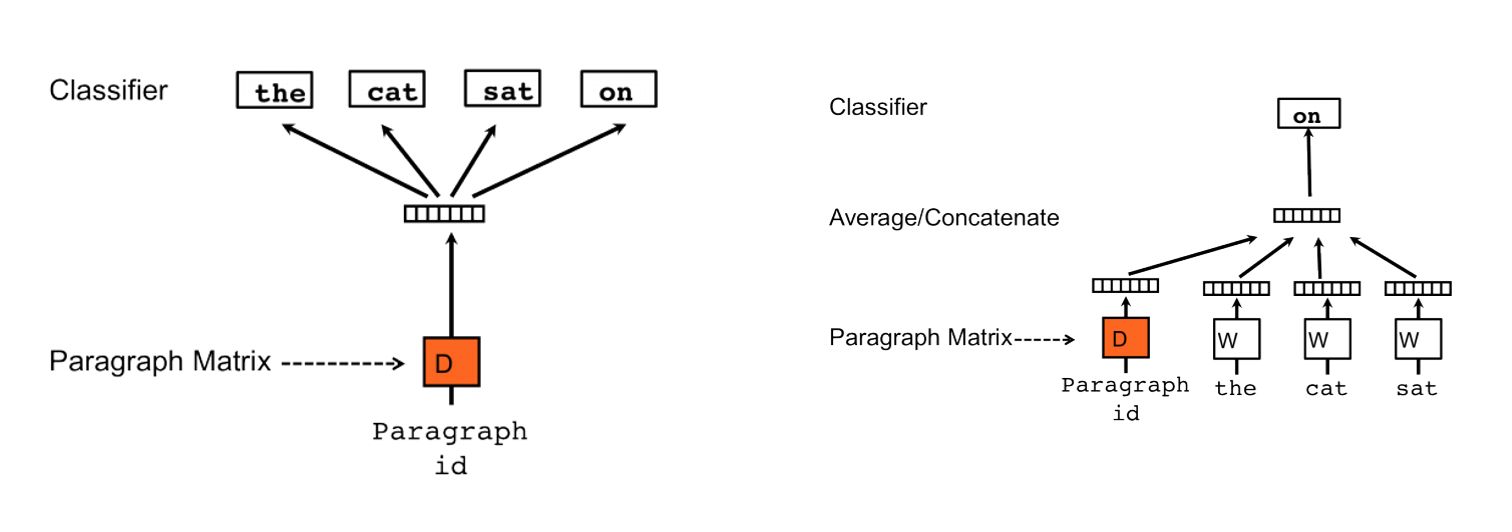
- Doc2Vec - Doc2vec é um algoritmo de aprendizagem não supervisionado para produzir representações vetoriais de frases / parágrafos / documentos. Esta é uma adaptação do word2vec que pode representar documentos inteiros em um vetor. Portanto, não precisamos calcular a média dos vetores de palavras para criar o vetor do documento.
from gensim.models.doc2vec import Doc2Vec, TaggedDocument
- BERT- Bidirectional Encoder Representation from Transformers (BERT) é uma técnica de ponta para pré-treinamento de processamento de linguagem natural desenvolvida pelo Google. BERT é treinado em texto não rotulado, incluindo Wikipedia e Book corpus. BERT usa arquitetura de transformador, um modelo de atenção para aprender embeddings para palavras. BERT consiste em duas etapas de pré-treinamento, Modelagem de Linguagem Mascarada (MLM) e Previsão de Próxima Sentença (NSP). No BERT, o texto de treinamento é representado usando três embeddings, Token Embeddings + Segment Embeddings + Position Embeddings.
Jupyter notebook com exemplos -> https://github.com/varun21290/medium/blob/master/Document%20Similarities/Document_Similarities.ipynb

Esse jupyter notebook com exemplos foi o que eu usei como base para montar o meu teste
ResponderExcluir