AI technologies
- natural language understanding,including Entity Recognition and Desambiguation (ERD) and concept detection, in extracting factoids from individual articles at the web scale,
- knowledge assisted inference and reasoning in assembling the factoids into a knowledge graph (MAG), and
- a reinforcement learning approach to assessing scholarly importance for entities participating in scholarly communications, through a probabilistic measure called the saliency, that serves both as an analytic and a predictive metric in MAS.
Challenge in the study of science of science is the explosive growth in the volume of scientific reports and the diversity of research topics. These have outstripped the cognitive capacity of human beings to properly digest and catch up.
Microsoft Academic Services (MAS) consists of three parts:
- an open dataset known as Microsoft Academic Graph (MAG),
- a freely available inference engine called Microsoft Academic Knowledge Exploration Service (MAKES),
- and a website called Microsoft Academic (MA) that provides a more human friendly interface to MAKES.
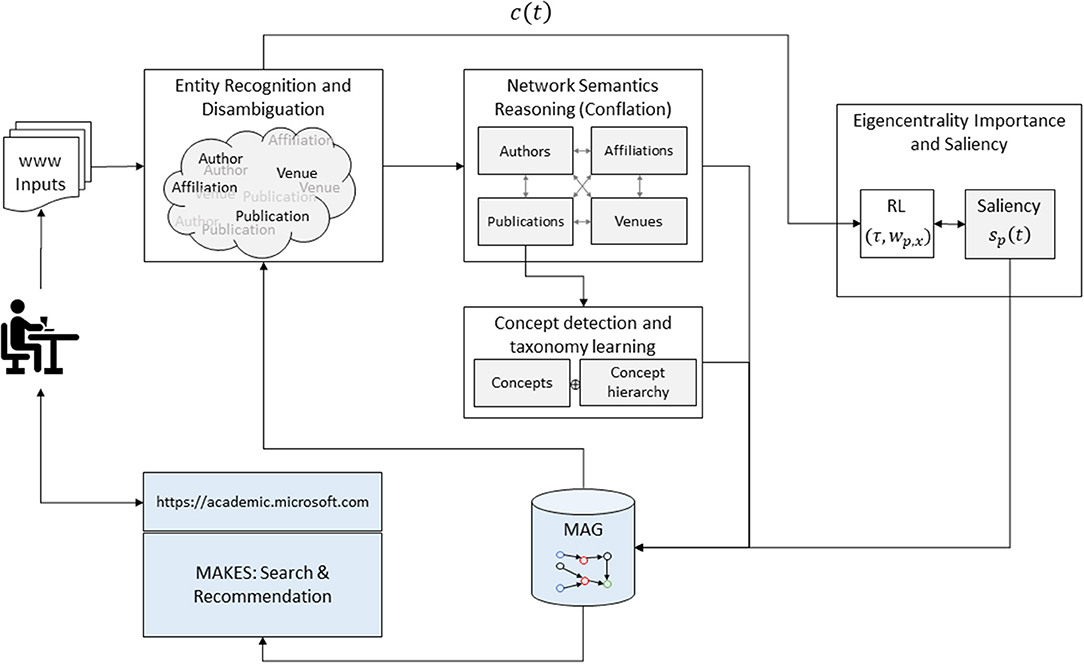
AI and service components in MAS are comprised of two feedback loops, one to grow the power of acquiring knowledge in MAG and the other to assess the saliency of each entity in MAG. In the first loop, each publication on the web is first processed by the MAG assisted entity recognition and disambiguation (ERD). As the raw entities and their relations are extracted from individual publications, semantic reasoning algorithms are then applied to conflate them into a revised graph, including the concept hierarchy from all the publications. The revised MAG is then used in the next run to better extract entities from publication. The second loop utilizes the citation behaviors as the rewarding target for a reinforcement learning algorithm to assess the importance of each entity on MAG based on the network topology. The quantitative measure, called the saliency, serves as a ranking factor in MAKES, a search and recommendation engine for MAG.
MAS is a part of an ongoing research that explores the nature of cognition, a topic in artificial intelligence (AI) that studies the mental capacity in acquiring, reasoning and inferencing with knowledge.
MAS aims at developing AI agents that are well-read in all scientific fields and hopefully can become trustable consultants to human researchers on matters of scholarly activities taking place on the web. In this sense, the MAG component in MAS is the outcome of the knowledge acquisition and reasoning and MAKES, the capability of machine inferencing with the knowledge in MAG. The dataset MAG is distributed and frequently updated under an open data license and the inference algorithms in MAKES are published in relevant peer-review venues.
To address the explosive growth in scientific research, MAS employs the state-of-the-art AI technologies, such as natural language understanding, to extract the knowledge from the text of these publications. This allows MAS to always take a data-driven approach in providing consistent data quality and avoid manual efforts that are often the source of subjective controversies or errors. Knowledge extraction in MAS goes beyond simply indexing key phrases to recognize and disambiguate the entities underpinning scholarly communications.
Entity Recognition and Disambiguation (ERD)
The semantic language model characterizes how frequently a sequence of semantic objects y is expressed through the word sequence x. Typically, an entity is lexicalized by a noun phrase while a relation, a verb phrase. MAS, however, does not utilize the syntax structure of natural language ....
Essentially, the semantic language model characterizes the synonymous expressions for each semantic object ei and how likely each of them is used. For example, the journal “Physical Review Letters” can be referred to by its full name, a common abbreviation “Phys Rev Lett,” or simply the acronym “PRL,” and an author can be mentioned using the last name, the first name or just its initial with an optional middle initial.
In conjunction with the synonym model, the semantic cohesion model can be estimated directly from data with an additional constraint that assigns zero probability to implausible semantic object combinations. This constraint plays a critical role in reducing the degree of ambiguities in understanding the input. For example, “Michael Evans” with a missing middle initial is a very confusable name, and “WWW” can mean a conference organized by IW3C2, a journal (ISSN: 1386-145X or 1573-1413), or even as a key word in the title of a paper. However, there are only two authors, a “Michael P. Evans” and a “Michael S. Evans” that have ever published any papers in the WWW conference, in 2002 and the other in 2017, respectively, and never in the namesake journal or any paper containing “WWW” as a key term in all other publication venues.
This capability in acquiring new knowledge without human intervention is the key for MAS to enrich itself gradually. (Caminho contrário do HITL)
Concept Detection and Taxonomy Learning
MAS adopts an entity type, called concepts [called “fields of study” in Sinha et al. (2015)], to represent the semantic contents of a document. (Bucsc@xxxx é um buscador que dado um campo de pesquisa visa encontrar os pesquisadores da PUC-RIO que trabalham com aquele campo)
Unlike physical entities such as authors and affiliations, concepts are abstract and hence have no concrete way to define them. Furthermore, concepts are hierarchical in nature. .... Accordingly, a taxonomy must allow a concept to have multiple parents and organize all concepts into a directed acyclic graph (DAG). While concepts can be associated with all types of physical entities, say, to describe the topics of interest of a journal or the fields of expertise of a scholar, MAS only infers the relations between a publication and its concepts directly and leaves all others to be indirectly aggregated through publications.
A survey on the concepts taxonomy used in major library systems, presumably developed by human experts, suggests that few of them are compatible with each other. The low agreement among human experts leads MAS to create a concept taxonomy by itself solely from the document collection.
Concept detection is a natural language understanding problem and, therefore, its mathematical foundation is also governed by a maximum a posteriori (MAP) decision problem.
... the key concept underlying the MAS approach here is the distributional similarity hypothesis proposed in 1950's (Harris, 1954), which observes that semantically similar phrases tend to occur in similar contexts. There have been plenty of methods reported in the literature demonstrating the efficacy of applying distributional similarity for concept detection, either by training a hierarchical classifier mapping a sequence of discrete words directly into concepts, or by the embedding method that first converts the text into a vector representation with which learning and inferences can be conducted in a vector space ...
The current practice in MAS, however, has found it more powerful to combine both the discrete and the vector space approaches into a mixture model for concept learning ... The concept detection software in MAS has been released as part of the MAG distribution. The package, called Language Similarity, provides a function with which the semantic similarity of two text paragraphs can be quantified using the embedding models trained from the publications in the corresponding MAG version. This function in turn serves as a mixture component for another function that, for any paragraph, returns a collection of top concepts detected in the paragraph that exceed a given threshold.
Network Semantics Reasoning
As MAS sources its materials from the web notorious for its uneven data qualities, duplicate, erroneous and missing information abounds. Critical to MAS is therefore a process, called conflation, that can reason over partial and noisy information to assemble the semantic objects extracted from individual documents into a cohesive knowledge graph. A key capability in conflation is to recognize and merge the same factoids while adjudicating any inconsistencies from multiple sources ... (Integração dos Dados a nível de instâncias: Fusão de Dados)
similar nodes tend to have similar types of edges connecting to similar nodes. Similar to the natural language use case of representing entities and relations as vectors, the goal of this approach is to transform the nodes and edges of a network into vectors so that reasonings with a network can be simplified and carried out in the vector space with algebraic mathematics.
The research in heterogenous network semantics reasoning, especially in its subfields of network and knowledge graph embedding, is ongoing and highly active. (Temas de pesquisa que podem ter problemas interessantes)
MAS has been testing the network embedding techniques on related entity recommendation and found it essential for each entity to have multiple embeddings based on the types of relations involved in the inferences. In other words, embedding is sensitive to the sense defining similarity. For example, two institutions can be regarded as similar because their publications share a lot in common either in contents, in authorships, in venues, or are being cited together by same publications or authors.
Assessing Entity Importance With Saliency
The prior should be the importance the entity has been perceived by the scholarly community in general.
Altmetrics is a good indicator gauging how a publication has gained awareness in the social media but the current focus in MAS is on exploiting the heterogeneity of scholarly communications to estimate the entity prior by first computing the importance of a node relative to others of the same type and then weighting it by the importance of its entity type.
Saliency: An Eigencentrality Measure for Heterogeneous Dynamic Network
Eigencentrality measures the importance of a node relative to others by examining how strongly this node is referred to by other important nodes. Often normalized as a probabilistic measure, eigencentrality can be understood as a likelihood of a node being named as most important in a survey conducted on all members in the network. The method is made prominent by Google in its successful adaptation of eigencentrality for its PageRank algorithm: the PageRank of a webpage is measured by the proportional frequency of the incoming hyperlinks weighted by the PageRank of the respective sources.
There are, however, two major challenges in using the eigencentrality as an article-level metric in general. Scientists only follow the bibliography half the time, with the other half randomly discovering articles from the entire research literature following a uniform distribution. And how to avoid treating eigencentrality as a static measure so that the time differences in citations can be taken into account. It is undesirable to treat an article that receives the last citations long ago as equal to one that has just received the same amount of citations today because results without a proper temporal adjustment exhibit a favorable bias toward older publications that have more time to collect citations.
MAS attacks these two challenges with a unified framework called saliency based on the following considerations. First, to address the underlying network as changing in time, saliency is defined as the stochastic process characterizing the temporal evolution of the individual eigencentrality computed from a snapshot of the network. Secondly, to account for the heterogeneity of the network, MAS uses a mixture model in which the saliency of a publication is a weighted sum of the saliencies of the entities related to the publication. By considering the heterogeneity of scholarly communications, MAS allows one publication to be connected to another through shared authors, affiliations, publication venues and even concepts, effectively ensuring the well-connectedness requirement is met.
As the heterogeneous model treats the saliency of a publication as the combined saliencies of all entities related to it, sp(t) is therefore a joint probabilistic distribution.
Estimating Saliency With Reinforcement Learning
To avoid making a strong assumption that the latent variables are constant, MAS uses reinforcement learning (RL) to dynamically choose the best values based on the reinforcement signals streaming in through the observations. The choice is motivated by the fact that the RL technique is known to be effective in tackling the exploitation vs. exploration tradeoff, which in MAS means a balanced treatment between the older and newer publications or authors that have unequal time to collect their due recognitions.
Properties of Saliency
Three citation behaviors not considered in the simple citation count: the number of mentions in the citing article, the age of the citations received, and the non-citation factors that can alleviate the disadvantages for newer publications. A quick examination into the disagreements confirms that a publication can have a higher saliency, albeit lower citation counts, because it is cited by more prestigious or more recent work as designed.
The design to unshackle the reliance on the overly reductive citation counts may also lead the saliency to be less susceptible to manipulations, ranging from citation coercions (Wilhite and Fong, 2012) to malicious cheating (López-Cózar et al., 2014) targeting metrics like the h-index. By using the citation contexts in saliencies, these manipulations are, in theory, less effective and easier to detect, as demonstrated by PageRank for the link spam detection in the web graph (Gyöngyi and Garcia-Molina, 2005). The extent to which the gain of the eigenvector-based method can be transported from the web graph to the scholarly network, however, awaits further quantification.
Another research topic MAS can be useful is in the effectiveness of saliencies of non-publication entities that, as described in (7), are aggregated from publication saliencies. This design gives rise to at least two intriguing properties. First, an entity can achieve high saliency with lots of publications, not all of which are important. The drawbacks of the h-index, e.g., capping at the publication counts in this example, are well-known (Waltman and Eck, 2012). By considering more factors and not limited to overly reductive raw signals, saliency appears to be better equipped to avoid mischaracterizing researchers who strive for the quality and not the quantity of their publications.
Secondly, because the underlying foundation of an aggregated saliency is based on article-level analysis, interdisciplinary work seems to be better captured. One such example is the journal ranking on a given subject, say, Library Science. As shown for a while at Microsoft Academic website8, journals like Nature and Science are among the top 10 for this field when ranked by saliency. ... Again, this example highlights the known problem of using journals as the unit to conduct quantitative scientific studies, and the sharp focus into article-level analysis, as demonstrated feasible by saliency, appears to be a better option.
Prestige: Size-Normalized Saliency
A known issue existing in aggregate measurements is that the sheer number of data points being considered can often play an outsized role. An author can reach a high saliency by having a large number of publications despite most of them receive only moderate recognitions. Given it has been observed that hyper-prolific authors exist (Ioannidis et al., 2018), and their publications seem to yield uneven qualities (Bornmann and Tekles, 2019), it might be helpful to juxtapose the saliency with a corresponding size-normalized version, which we call prestige, to further discern the two aspects. In short, the prestige of an entity is the average of the saliencies of its publications. Size normalization, as expected, significantly boosts their rankings, for instance, as in the cases of Princeton University and Google.
Fonte: https://www.frontiersin.org/articles/10.3389/fdata.2019.00045/full
https://doi.org/10.3389/fdata.2019.00045


the semantic cohesion model -> encontrar um caminho no grafo que ligue os nós mapeados pelas palavras chaves
ResponderExcluir