Durante um projeto de pesquisa podemos encontrar um artigo que nos identificamos em termos de problema de pesquisa e também de solução. Então surge a vontade de saber como essa área de pesquisa se desenvolveu até chegar a esse ponto ou quais desdobramentos ocorreram a partir dessa solução proposta para identificar o estado da arte nesse tema. Podemos seguir duas abordagens:
- realizar uma revisão sistemática usando palavras chaves que melhor caracterizam o tema em bibliotecas digitais de referência para encontrar artigos relacionados ou
- realizar snowballing ancorado nesse artigo que identificamos previamente, explorando os artigos citados (backward) ou os artigos que o citam (forward)
Mas a ferramenta Connected Papers propõe uma abordagem alternativa para essa busca. O problema inicial é dado um artigo de interesse, precisamos encontrar outros artigos relacionados de "certa forma".
- Find different methods and approaches to the same subject
- Track down the state of the art research in the field
- Identify seminal works and background reading
- Explore and immerse ourselves in the topic and become aware of the trends and dynamics in the literature
O primeiro passo é analisar as citações desse artigo e encontrar, dentro de uma base de aproximadamente 50 mil artigos, o conjunto de artigos mais próximos desse artigo. Mas o relacionamento entre artigos não é de citação simples (não faz snowballing) nem de comparabilidade com trabalhos relacionados ou até mesmo comparação do conteúdo do texto (frequência de termos).
Connected Papers is not a citation tree. Those have been done before.
A similaridade entre eles é calculada por citação compartilhada, ou seja, se dois trabalhos possuem um alto índice de compartilhamento de citações então tendem a tratar de assuntos similares.
To get a bit technical, our similarity is based primarily on the concepts of co-citation and bibliographic coupling (aka co-reference).
A base de artigos vem crescendo a medida que novos parceiros se juntam ao projeto (ArXiv e Semantic Scholar por exemplo).
Obs.: não encontrei qual seria o parâmetro para o corte do conjunto de artigos relacionados que compõem o grafo, não sei se é um número máximo de conexões ordenadas por essa similaridade (top K) ou se é uma métrica de similaridade mínima (threshold).
No grafo resultante (como na imagem abaixo) cada artigo relacionado é apresentado como um nó com uma cor para o ano e um tamanho correspondente ao número de citações. As arestas representam o "grau de similaridade" de citações comuns entre cada nó, quanto mais similares mais próximos no espaço e mais "grosso" o desenho da aresta.
Obs.: talvez a métrica de similaridade seja Jaccard (interseção das citações comuns dividida para união das citações) mas ainda preciso confirmar isso.
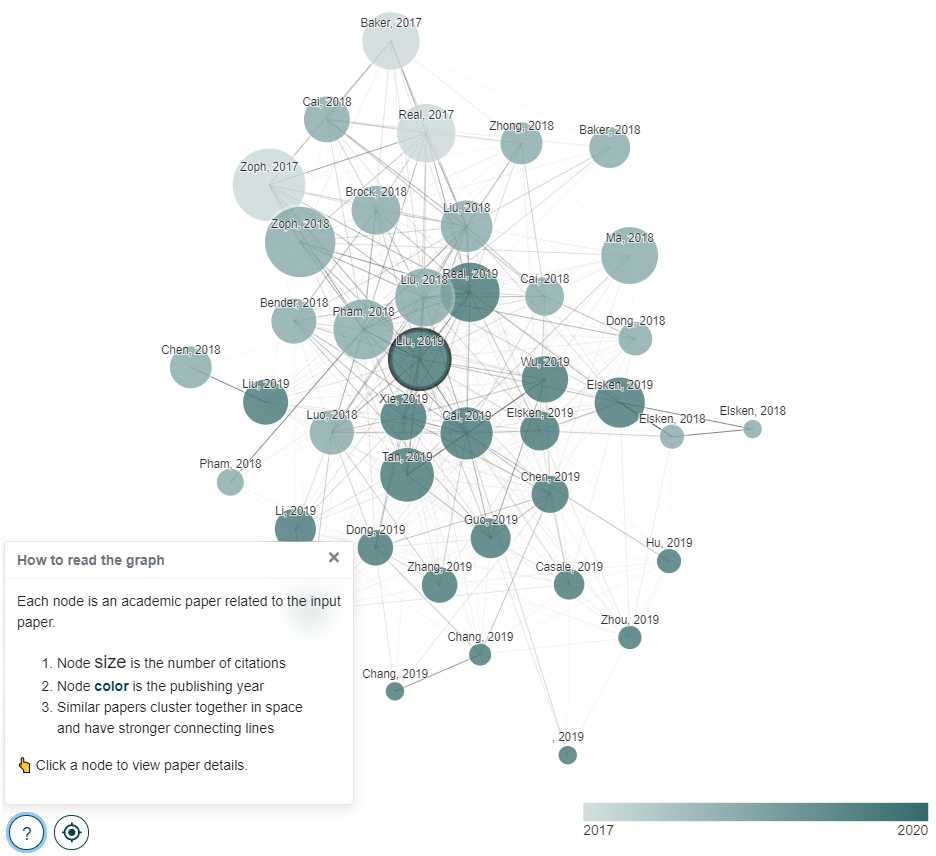
With our layout algorithm, similar papers cluster together in space and are connected by stronger lines (edges). Popular papers (that are frequently cited) are represented by bigger circles (nodes) and more recent papers are represented by a darker color.
Importante destacar que nesse grafo existem artigos que não estão relacionados diretamente com o artigo original mas estão relacionados indiretamente através de outros artigos similares. Com isso ao clicar em um nó o caminho mais curto entre esse nó e o artigo original é destacado.
Duas visões adicionais em lista são fornecidas: Trabalhos Anteriores e Derivados. Como trabalhos anteriores são apresentados os trabalhos mais citados do conjunto de trabalhos que formam os nós do grafo, entre estes estão provavelmente os trabalhos seminais. Como trabalhos derivados são apresentados os trabalhos que mais citam os trabalhos que formam os nós do grafo, entre estes estão provavelmente os estudos secundários como surveys e também trabalhos mais recentes com o estado da arte na área.
A ferramenta também permite o download da lista de artigos em formato .bib para ser importado em gerenciadores de referência de preferência além de acompanhar a evolução do grafo ao longo do tempo.
Fontes:
https://medium.com/connectedpapers/announcing-connected-papers-a-visual-tool-for-researchers-to-find-and-explore-academic-papers-89146a54c7d4
Testando a ferramenta:
Artigo de entrada: UMLtoGraphDB: Mapping Conceptual Schemas to Graph Databases
Grafo de saída:

Observações: somente um outro artigo apresentava a palavra chave graph, nenhum outro continha model ou UML no título mas vários apresentavam a palavra keyword (????). Parece que com esse exemplo foi selecionado o nó origem não como o artigo isolado mas sim o Proceedings Conference do ER 2016 e esse nó ficou completamente isolado do resto do cluster (?????). Esperava um resultado que me permitisse comparar com a revisão sistemática que fiz sobre Data Modeling of Connected Data. O artigo que usei de entrada foi um dos selecionados na revisão e que era citados por outros artigos também selecionados. Mas talvez por ser uma publicação da Springer exista alguma dificuldade em obter as citações.
Artigo de entrada: A Survey on Data-driven Performance Tuning for Big Data Analytics Platforms
Grafo de saída: Não gerou pq não consta no Semantic Scholar
Artigo de entrada: ZHENG, W. et al. Semantic SPARQL similarity search over RDF knowledge graphs. Proceedings of the VLDB Endowment, [s.l.], vol. 9, no. 11, p. 840–851, 2016. ISSN: 21508097, DOI: 10.14778/2983200.2983201
Grafo de saída:

Observações: o artigo inicial está praticamente no centro da imagem do grafo (e não isolado como no primeiro teste). O conjunto de 41 publicações que compõem os nós do grafo variam de 2013 a 2020. A maior parte dos títulos das publicações selecionadas contém palavras como RDF e search e a métrica de similaridade em relação ao artigo inicial varia de 16.5 a 7.6. No conjunto "trabalhos derivados" temos de 7 a 4 trabalhos do conjunto do grafo sendo citados e no conjunto "trabalhos prévios" temos que 10 a 18 trabalhos do conjunto do grafo citam os mesmos. Baixei os 3 conjuntos em formato .bib e carreguei as referências no Mendeley, totalizando 58 artigos. Depois de remover 4 artigos duplicados, restaram 54 artigos de 2002 a 2020.
Contato com os desenvolvedores:
We currently do not share details about our technology implementation beyond what can be found in our about page and medium blog posts, though we are considering writing a blog post explaining more of the technology in the future.

A ferramenta está disponível em uma aba do ArXix chamada Related Papers.
ResponderExcluirEstou inscrita na newsletter caso tenham alguma novidade
De abril para cá nenhuma comunicação foi feita. Existem alterações registradas no release notes -> https://www.notion.so/Connected-Papers-Release-Notes-f758d434dfcc45e2b8ed3d0452739982
ExcluirUm vídeo sobre a ferramenta -> https://youtu.be/nAWR2auL_6E
ResponderExcluir