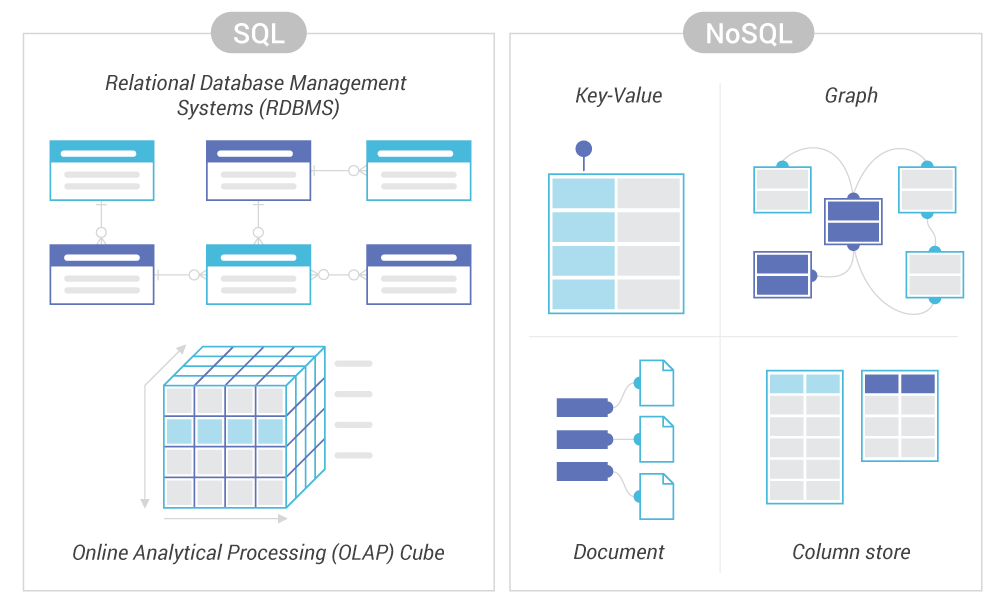
 |
| https://www.scylladb.com/resources/nosql-vs-sql/ |
A Workload-driven Document Database Schema Recommender (DBSR)
- https://youtu.be/APVlxebtmLI
Aggregate oriented modeling
Input: ER Model, Read Workload (JOIN), Configurations
First step: create a Normalize document structure and analyze the JOIN steps
Refinements of query plans removing JOINS and embeddings documents, merging document structures based on entities relationships, in order to reduce Read Operations costs
Outuput: Doument collections, query plans (with indexes) and utility matrix of recommendations
An Empirical Study on the Design and Evolution of NoSQL Database Schemas
- https://youtu.be/Mz7P6pp5TvY
Lack of empirical study in NoSQL
10 selected projects from GitHub: denormalized is commom but it isn't a rule, NoSQL takes longer to stabilize compared to SQL (in general), change the type of the attribute is more frequent than other schemas changes
Neo4j Keys
https://youtu.be/qQQ9DuBPIrU
Neo4J key = label + property attributes
Complete: all node have
Uniqueness: there is no two or more nodes with the value
Neo4J don't support multi-label key
Discovering Data Models from Event Logs
- https://youtu.be/J2nxUxE-r_I
Process Model and Data Model
Step 1 => Input: Event Log Output:A2A Diagram = Activities x Attributes relationship
Four rule to separate A2A

Esse que usou o GitHub é bem interessante pq partiu de projetos de aplicações e conseguiu identificar um padrão de comportamento para NoSQL
ResponderExcluir