Site do Workshop
https://sites.google.com/view/comonos20/home
Artigos aceitos
Pablo D. Muñoz-Sánchez, Carlos Javier Fernández Candel, Jesús García-Molina and Diego Sevilla Ruiz. Extracting Physical and Logical Schemas for Document Stores.
Pavel Čontoš and Martin Svoboda. JSON Schema Inference Approaches.
Alberto Hernández Chillón, Diego Sevilla Ruiz and Jesus Garcia-Molina. Deimos: A Model-based NoSQL Data Generation Language.
Dois sobre engenharia reversa aplicados a Document Stores
Invited Talk
Pascal Desmarets (Hackolade): NoSQL Data Modelling in Practice
Vídeo -> https://drive.google.com/file/d/1Sps7qS4yfG-KEXaDdYuopDP-SzMqP1QN/view
Apresentação -> https://drive.google.com/file/d/1mOc_Zv_u9i4d84cJHvSGW56V-OQ_rACg/view
Considerações:
Agile x Data Modeling as a bottleneck.
Low ROI of Big Data projects
The tree phases of traditional Data Modeling should be redesigned to two: Domain-Driven Design (technology agnostic) + Physical Schema Design (application-specific) **
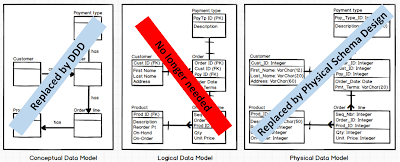
Aggregation is the opposite of Normalization and reduces (eliminates!) impedance mismatch of data (physical schema) and objects (application)
Schemaless is misinterpreted and flexibility is not easy to deal. How to process empty, missing or null attributes? How to express relationships: referencing ou embedding? How to use polymorphic data types and check its quality?
Reverse-Engineering whithout DDL: probabilistic schema inference, required x optional, polymorphism, pattern detection, relationships
Schema inference meta model (slide 48)
The term schema-on-read is not accurated since the time you store data there is a schema.
Graph should be divided into LPG and RDF
Obs1. o apresentador escreveu outro artigo: Data Modeling Is Dead…Long Live Schema Design!
- https://medium.com/hackolade/data-modeling-is-dead-long-live-schema-design-4c1aed88cc21
- https://www.datastax.com/resources/video/datastax-accelerate-2019-data-modeling-dead-long-live-schema-design
Some quotes from these articles
** Logical modeling makes sense when aiming to achieve an application-agnostic database design, which is still best served by relational database technology.
DDD consists of a collection of patterns, principles, and practices that enable teams to focus on what’s core to the success of the business while crafting software that tackles the complexity in both the business and the technical spaces. One such pattern is an aggregate, a cluster of domain objects that can be treated as a single unit, for example an order and its order lines
Obs2. e representa uma empresa que desenvolveu uma ferramenta de modelagem NoSQL (polymorphic data modeling) e tem treinamentos nessa área.
- https://hackolade.com/
- https://hackolade.com/training.html

Comentários
Postar um comentário
Sinta-se a vontade para comentar. Críticas construtivas são sempre bem vindas.