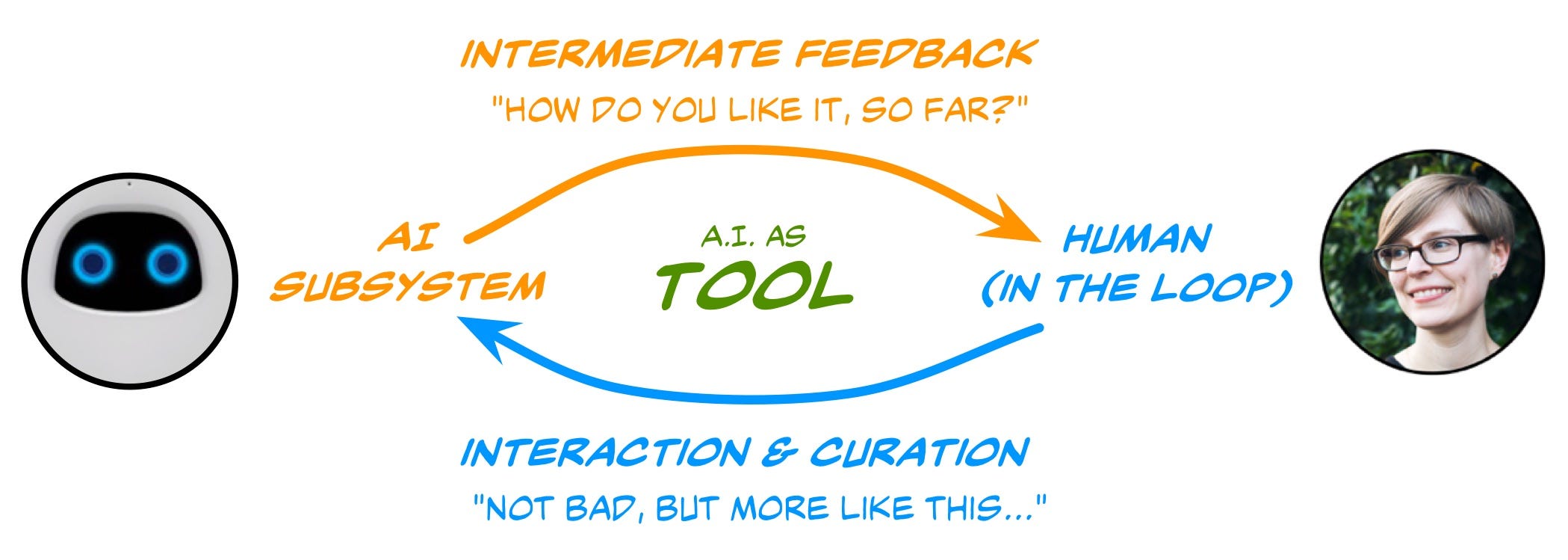
O Human-in-the-loop (HITL) é um ramo da inteligência artificial que aproveita a inteligência humana e de máquina para criar modelos de aprendizado de máquina. Em uma abordagem tradicional do HITL, as pessoas estão envolvidas em um círculo virtuoso, onde treinam, sintonizam e testam um algoritmo específico.
Geralmente, funciona assim:
Primeiro, os seres humanos rotulam dados. Isso fornece ao modelo uma alta qualidade e quantidade de dados de treinamento. Um algoritmo de aprendizado de máquina aprende a tomar decisões com base nesses dados.
Em seguida, os seres humanos ajustam o modelo. Isso pode acontecer de várias maneiras diferentes, mas geralmente os humanos atribuem uma pontuação aos dados para indicar excesso de ajuste (overfitting), para ensinar um classificador sobre casos extremos (outlier) ou novas categorias no âmbito do modelo.
Por fim, as pessoas podem testar e validar um modelo atribuindo uma pontuação ao resultado, especialmente em casos onde um algoritmo não tem confiança em um classificação ou confia demais em uma decisão incorreta.
Agora, é importante observar que cada uma dessas ações compreende um loop de feedback contínuo. O aprendizado de máquina HITL significa pegar cada uma dessas tarefas de treinamento, ajuste e teste e alimentá-las de volta no algoritmo para que fique mais inteligente, mais confiante e mais preciso. Isso pode ser especialmente eficaz quando o modelo seleciona o que ele precisa aprender a seguir - conhecido como aprendizado ativo - e você envia esses dados aos anotadores humanos para treinamento.
HITL on Amazon AWS - https://youtu.be/rJw7u8qyDf4
Dicionario de Crowdsourcing - https://www.clickworker.com/crowdsourcing-glossary/human-in-the-loop/


Comentários
Postar um comentário
Sinta-se a vontade para comentar. Críticas construtivas são sempre bem vindas.